承接前篇,透過寫好的外迴圈程式ithelp_wordcloudmand_2(),
得到了ithelp_wordcloudmand_t3_goalwarehouse將每個中文句子拆開,
往下接著我們要用內迴圈,做【逐字】、【逐字數】的處理。
在SQL迴圈實作 -4.關聯分析的處理工廠2有提到過,建置setof的用意,在於先建置出,下一步迴圈將要產出的所有欄位,好讓下一步的迴圈可以直接參照,迴圈只跑1次,和跑完成千上萬次,所產出的欄位都會相同,這步驟只需要隨便先跑某1次即可。
drop XXX if exists,意思就是如果存在,那就drop掉,如果不存在,那就忽略這條指令。第6步的這個段落不會看到前面2條function的建置過程,但為了維持完整性,我還是將整個語法貼上來,在此,先請各位專注在ithelp_wordcloudmand_t6_setof的建置內容。
顯然,我們要拿第5步已經處理完的ithelp_wordcloudmand_t3_goalwarehouse來做下一步處理。
DROP FUNCTION IF EXISTS ithelp_wordcloudmand_3(r int, s int);
DROP FUNCTION IF EXISTS ithelp_wordcloudmand_4(u int, v int);
DROP TABLE IF EXISTS ithelp_wordcloudmand_t6_setof;
CREATE TABLE ithelp_wordcloudmand_t6_setof as
select *,
SUBSTRING(goal,1,2) goal2,
LENGTH(SUBSTRING(goal,1,2))
from ithelp_wordcloudmand_t3_goalwarehouse
where LENGTH(SUBSTRING(goal,1,2)) =2
;
select * from ithelp_wordcloudmand_t6_setof
SUBSTRING(goal,1,2)
LENGTH(SUBSTRING(goal,1,2))
where LENGTH(SUBSTRING(goal,1,2)) =2
如上SQL語法,第一條,我只要針對goal這個欄位,從第1個字開始,往後取連續2個字(第1個字+第2個字),可以想像一下,1和2這個數字,在下一步,會成為變數,在迴圈中陸續跑......
從第2個字開始,往後取連續2個字、
從第3個字開始,往後取連續2個字、
從第4個字開始,往後取連續2個字......
...
從第2個字開始,往後取連續3個字、
從第3個字開始,往後取連續3個字、
從第4個字開始,往後取連續3個字......
...
第二條是為了知道自己會不會已經取到了最後,舉例goal某個內容只有4個字,而現在跑到了SUBSTRING(goal,4,2),那事實上它只會跑出最後1個字,長度也只有1,這並不是我們的目標,也因此,我們限定了where條件,必須要等於我取的字串長度才行。
執行SUBSTRING(goal,1,2)出來的結果如下: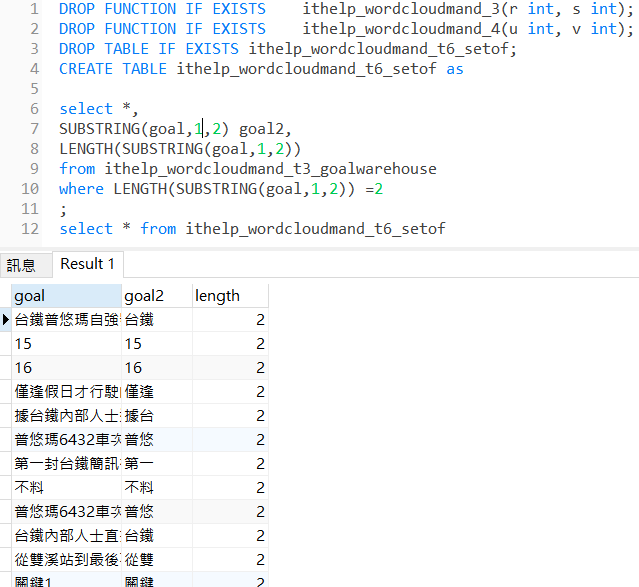
我們看看執行SUBSTRING(goal,2,2)會如何: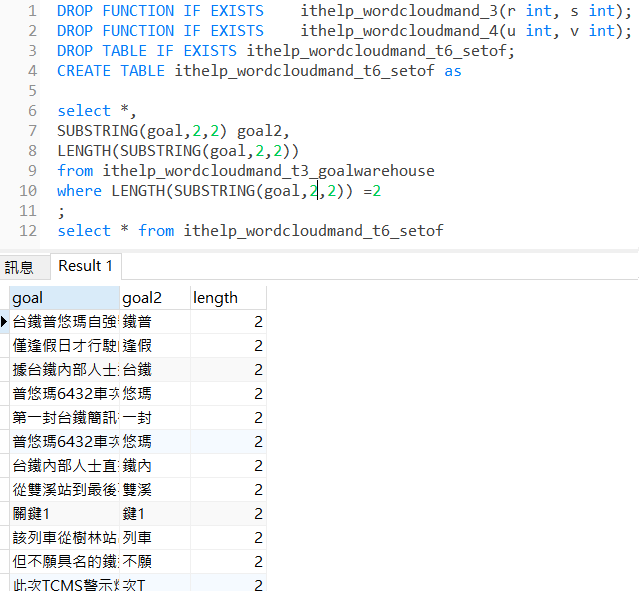
再次說明,內迴圈是以UNION的形式產出每一次的迴圈結果,可以想像一下,goal2,就是在迴圈結束後,我們將要拿來產生文字雲的資料,只是現在顯然還有很多的非單字,例如鐵普、逢假...,但不用擔心,這類型的非單字,在大量資料之下的筆數仍然相對低,而我們只需要找出現次數高的來看就可以了。
建立第一條ithelp_wordcloudmand_3(r int, s int):
----------以下開始ithelp_wordcloudmand_3(r int, s int)的設定----------
DROP FUNCTION IF EXISTS ithelp_wordcloudmand_3(r int, s int);
CREATE OR REPLACE FUNCTION ithelp_wordcloudmand_3(r int, s int)
RETURNS SETOF ithelp_wordcloudmand_t6_setof AS
$BODY$
BEGIN
RETURN query
--------------------以下開始SQL語法的設定--------------------
select *,
SUBSTRING(goal,r,s) goal2,
LENGTH(SUBSTRING(goal,r,s))
from ithelp_wordcloudmand_t3_goalwarehouse
where LENGTH(SUBSTRING(goal,r,s)) = s
--------------------以上結束SQL語法的設定--------------------
;
END
$BODY$
LANGUAGE 'plpgsql';
----------以上結束ithelp_wordcloudmand_3(r int, s int)的設定----------
由於前面談得非常詳細了,這邊我就不一一細講囉~
總之就是把前一步ithelp_wordcloudmand_t6_setof的SQL丟進去中間,
然後把原本是固定的數字(1,2)改成變數(r,s)。
接著,建立第二條ithelp_wordcloudmand_4(u int, v int):
----------以下開始ithelp_wordcloudmand_4(u int, v int)的設定----------
DROP FUNCTION IF EXISTS ithelp_wordcloudmand_4(u int, v int);
CREATE OR REPLACE FUNCTION ithelp_wordcloudmand_4(u int, v int)
RETURNS SETOF ithelp_wordcloudmand_t6_setof AS
$BODY$
BEGIN
FOR r IN 1..u
LOOP
FOR s IN 2..v
LOOP
RETURN query select * from ithelp_wordcloudmand_3(r,s);
END LOOP;
END LOOP;
END
$BODY$
LANGUAGE 'plpgsql';
----------以上結束ithelp_wordcloudmand_4(u int, v int)的設定----------
這邊s從2開始跑應該可以理解吧?畢竟現階段,我們不可能針對長度為1的中文字去做判斷。
如果對於內迴圈的寫法不太理解,建議可以重新看一下SQL迴圈實作 -5.關聯分析的處理工廠3的說明。
----------以下測試ithelp_wordcloudmand_4(u int, v int)的結果----------
select * from ithelp_wordcloudmand_4(50,8)
意思是,我從第1個字取到第50個字(超過範圍也無妨,反正where已經擋好了),從取長度為2,一直到取長度為8。而這是一份接近兩萬筆的資料,只要再針對goal2去group by,加些基本條件,文字雲的底階資料就產生了。
前面文章有提到過,內迴圈之所以稱「內」迴圈,在於我們可以知道它的範圍、知道它的終點,可以直接指定變數,不必去設定控制項。然而,我們仍然對於到底該從第1個字跑到第幾個字,有點懸念,所以我們偷看了一下......
select tag
from (
select MAX(LENGTH(goal)) over (PARTITION BY 1) tag
from ithelp_wordcloudmand_t3_goalwarehouse
) A
group by tag
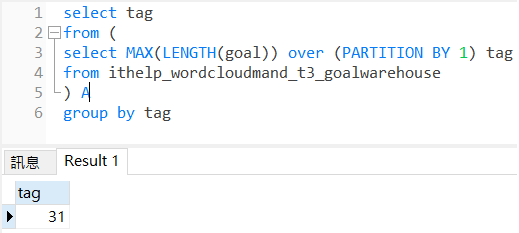
結果發現,「喔!原來最長的長度只有31呀!」
那就寫 select * from ithelp_wordcloudmand_4(30,8)就能得到和原本一樣的資料,31次之後都是白跑的。換句話說,我們可以設計以下的function:
----------以下開始ithelp_wordcloudmand_5()的設定----------
DROP FUNCTION IF EXISTS ithelp_wordcloudmand_5();
CREATE OR REPLACE FUNCTION ithelp_wordcloudmand_5()
RETURNS INTEGER as
$BODY$
BEGIN
--------------------以下開始SQL語法的設定--------------------
RETURN tag
from (
select MAX(LENGTH(goal)) over (PARTITION BY 1) tag
from ithelp_wordcloudmand_t3_goalwarehouse
) A
group by tag
--------------------以上結束SQL語法的設定--------------------
;
END
$BODY$
LANGUAGE 'plpgsql';
----------以上結束ithelp_wordcloudmand_5()的設定----------
第三排一樣是RETURNS INTEGER,然後把SQL丟進中間。
最後再把上面寫好的ithelp_wordcloudmand_5()丟進ithelp_wordcloudmand_4()裡,變成:
select * from ithelp_wordcloudmand_4(ithelp_wordcloudmand_5(),8)
就完成所有針對中文文字雲的內迴圈範圍設計了。
但至於為什麼是取8?其實沒有一定的標準,各位可以多方嘗試,說不定取4、取5就已經足夠了。可以發現,再往後的領域,還有非常多值得我們解析討論之處,可謂博大精深啊!
實際來看看成果吧!
DROP TABLE IF EXISTS ithelp_wordcloudmand_t8_goal;
CREATE TABLE ithelp_wordcloudmand_t8_goal as
select A.*
from(
select
goal2 goal,
SUM(1) cnt
from ithelp_wordcloudmand_4(ithelp_wordcloudmand_5(),8)
group by goal2
) A
where cnt >=2
order by cnt desc
;
select * from ithelp_wordcloudmand_t8_goal
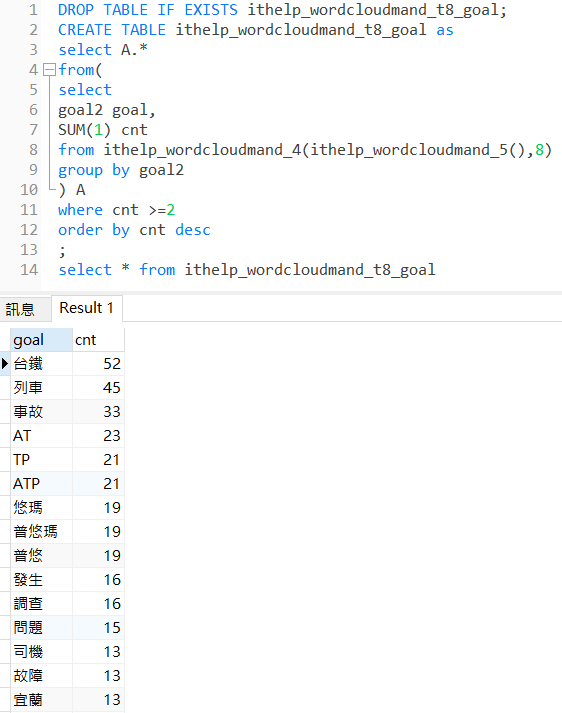
台鐵,在這篇文章出現了52次;列車,出現了45次;事故,出現了33次......文字雲的雛型已經誕生了!
而那些比較奇怪的非單字,出現次數的確不多。也可以透過where,去限制出現的次數要幾次(cnt)我們才看。但如同前面的為什麼是取8相同的概念,到底cnt要多少次、還是占多少比例,才會被拿來用?一樣是值得繼續深究的議題,在此就先不往下討論。
接下來,就剩一些必須的資料處理,例如處理字串長度是3的:將atp的變化包括at、tp,讓at和tp歸類成atp;普悠瑪的變化包括普悠、悠瑪,把普悠、悠瑪歸類成普悠瑪;司機員的變化是司機、機員,把司機、機員歸類成司機員。最終,我們就能作出「報導者-【普悠瑪18死事故】2通簡訊示警,關鍵53分鐘危機處理待調查」這篇文章如下的文字雲:
本篇文章重點,在於function內迴圈的應用,包括如何做出第一個含有SQL query的主要function,再做出第二個含有FOR...IN、LOOP...END LOOP的迴圈function,最後做出第三個返回整數的function去限制迴圈終點。
而不在繼續深入描寫【文字探勘(text mining)】的過程,畢竟mining的學問博大精深,光是day5~day8小馬我就花了四天去寫data mining,所以這邊就不再贅述內容。
也不在於視覺化的呈現該如何辦到,應該陸續以來的文章都有提到,我們目標只是做出【文字雲的底階資料】而非【怎麼畫出文字雲】,我上圖的文字雲是用Tableau製作的,只要有目標單字(goal)和次數(cnt),Tableau是很不錯的工具,當然你也可以網路找個HTML5寫好的文字雲產生器。
因此上述呈現,仍未臻完美境界,例如還有一些重複字句被重複運算、怎麼用SQL做歸類、歸類是歸類了但次數也被加總了等等,這些問題都可以透過後面持續加上SQL處理語法,進而去mining、去解決。只是若要連後面這些內容都丟上來寫,就顯得有點議題重複、大而無當了。
中文的系統處理至今仍然是一塊非常困難的領域,包括中譯、錄音轉文字稿、文字稿的勘誤、文字稿的關鍵字處理等等,會看到有公司躁進地想宣稱自己開拓並克服了這困難的領域,例如「人類冒充 AI 又一樁!語音辨識大廠「科大訊飛」的 AI 同步口譯是人類冒充的」文章中的狀況。
在文字雲的領域裡,小馬也常見以「關鍵字字庫」取代mining完的內容,去當作匹配文字雲內容的骨架。意思是,目標文章中有符合「關鍵字字庫」裡面單字的單字,才會呈現出文字雲。以現階段而言,這不失為一個解決辦法,好處是它不用去逐字、逐字串長度去看哪個單字最多,省去了mining過程的工及可能產生的效能問題,也加速了整個產出的過程;但壞處是一旦關鍵字字庫沒有包含到哪個單字,該單字縱使文章內出現得再多,它也不會浮出雲上。
因此無論如何,這種方式無法發展成真正的AI,因它是透過半人工的方式去建立。這概念非常像是擊敗傳奇圍棋棋王李世石的AlphaGO,剛開始的學習也是先閱讀人類棋譜,直到後來才開始讓完全沒有經驗的AI,不透過任何棋譜開始自學。
迴圈對於AI的重要性,就在於AI是透過某個程序不斷地去學習,硬要講,其實上面的文字雲處理就已經是個嬰兒AI,你可以想像第8步驟後我們持續掛上外迴圈,讓出現次數最多的單字,同樣依據goal-warehouse的概念,逐漸建成關鍵字字庫,當這嬰兒閱讀了夠多的文章,關鍵字字庫就會有越多完整的單字。
這時候再讓迴圈的執行,是以關鍵字字庫的方式去處理,加速增加更多的生字,進入到關鍵字字庫,你可以想像,總有一天,這嬰兒會成長為大人,而關鍵字字庫中,已經涵蓋了所有它曾經學習過,出現次數非常多的單字。
這時候再隨便丟一篇文章給它,難道它還會吐出「道英」、「文很」這種單字嗎?肯定就不會了。上述的這些文字說明,小馬一度很想要嘗試製作,無奈現今以小馬財力能購置得起的硬體配備,已不足以因應我這甚至稱不上偉大的計畫。
各位就知道,AI這條路,與其說還有非常長的一條路要走,不如說往後的發展是遙無止盡、看不見終點的,無論是軟體、硬體、或是開發人員的普及化。
進入到最後一天,勢必得呼應我的主題:
AI無法一步登天!
在「AI人工智慧 - Wiki」中,我對於「弱人工智慧」和「強人工智慧」有非常大的同感,這邊稍微說明一下。
指的就如我系列文實作的內容,所有的知識和學習過程,都是人類設定好的。當某天一篇文章丟給這個AI,它告訴你這篇文章的主要內容、甚至主要情感,都只因為背後人類已經設定好所有的變數和參數,讓這個AI呈現出「就像是人類一樣」的表現。
當然,透過系統的處理,AI已經能做到超越人類極限的事情,例如,將圍棋棋盤上面的所有變化釐清,並知道每一步棋的勝率,這件事人類已經做不到......但...與其說做不到,不如說是因為人類沒有那麼長的時間和那麼大的腦容量可以去儲存,這是【人類硬體】的限制。
指的是超越人類設定,自行演化成另一種自我意識。就像是我舉例的,不透過人為設定,系統可以自行判斷這篇文章是英文所以只需要走5個步驟、這篇文章是中文所以需要走8個步驟而且後面還有很多的mining工。我明明是丟圍棋棋譜和一些圍棋新聞給這AI,結果AI最後決定跑去打LOL(英雄聯盟),還打上了鑽石菁英?
呃...我就不繼續說下去,因為實在太荒謬了,這是我說的「外星生物」,而不是「人工智慧」。
很顯然,小馬是個「弱人工智慧」的擁護者,甚至,小馬認為,會覺得AI能發展成「強人工智慧」的,肯定不是這領域的開發者,因為他們根本沒有概念,該怎麼做到這件事。但「弱人工智慧」完全是可以被開發出來的,因為它有一定的範圍限制,也有一定的脈絡可循,最重要的是這兩個字:踏實。
講得更白話一些,原本人類「看得到、吃不到」的範圍,可以由人工智慧去實現,例如我說的圍棋全部的變化;但人工智慧不可能發展出,超越人類給它的限制範圍。
至於AI會不會取代人類工作?這是非常根本的假議題。
還記得出現在資料分析(Data Analysis) -6.小結裡的報表小公主嗎?
不用到AI,他們就已經被取代了。
還不是AI,只是BI而已。
隨著時代演變、科技進展,本來就會有很多工作將被取代掉,
就像是相機底片、像是一些夕陽產業一樣,而根本與AI不AI無直接干係。
這整篇的內容再次爆字數了,IT邦的系統算下來已經超過九千字。原本是打算拆成最後5天的內容,但為了將外迴圈的例子給放進系列文裡,全部濃縮在這篇。
很高興有這鐵人賽,一方面回顧了自己踏入IT的歷史、也檢驗了自己功力如何、所在階段如何,30天總字數超過六萬,拆開來夠我參加好幾屆鐵人賽(還有人私下叫我不要那麼浪費啊!!),不過我重點更在宣揚自己理想,並尋個能完整闡述的地方,再次感謝有IT邦幫忙這個平台,感謝各位包容小馬30天以來的大放厥詞。明年後年更久以後,可能會再見,也可能不會。謝謝大家!Bye-Bye!
上一篇:
SQL迴圈實作 -9.中文文字雲的處理工廠2
下一篇:
完整目錄
恭喜大大完賽,可惜就這樣結束啦...
啊...是指還有什麼【原本認為我應該要寫上來,卻沒有寫到的】是嗎?我以為涵蓋的範圍已經蠻多的(不過確實只談了我想談的部分),感謝觀看和指教啦~~~

